Ensembling with Deep Generative Views
Lucy Chai1,2
Jun-Yan Zhu2,3
Eli Shechtman2
Phillip Isola1
Richard Zhang2
1MIT 2Adobe Research 3CMU
CVPR 2021
[Paper]
[Code]
[Colab]
[Bibtex]
Skip to:
[Abstract]
[Summary]
[Video & Poster]
Abstract:
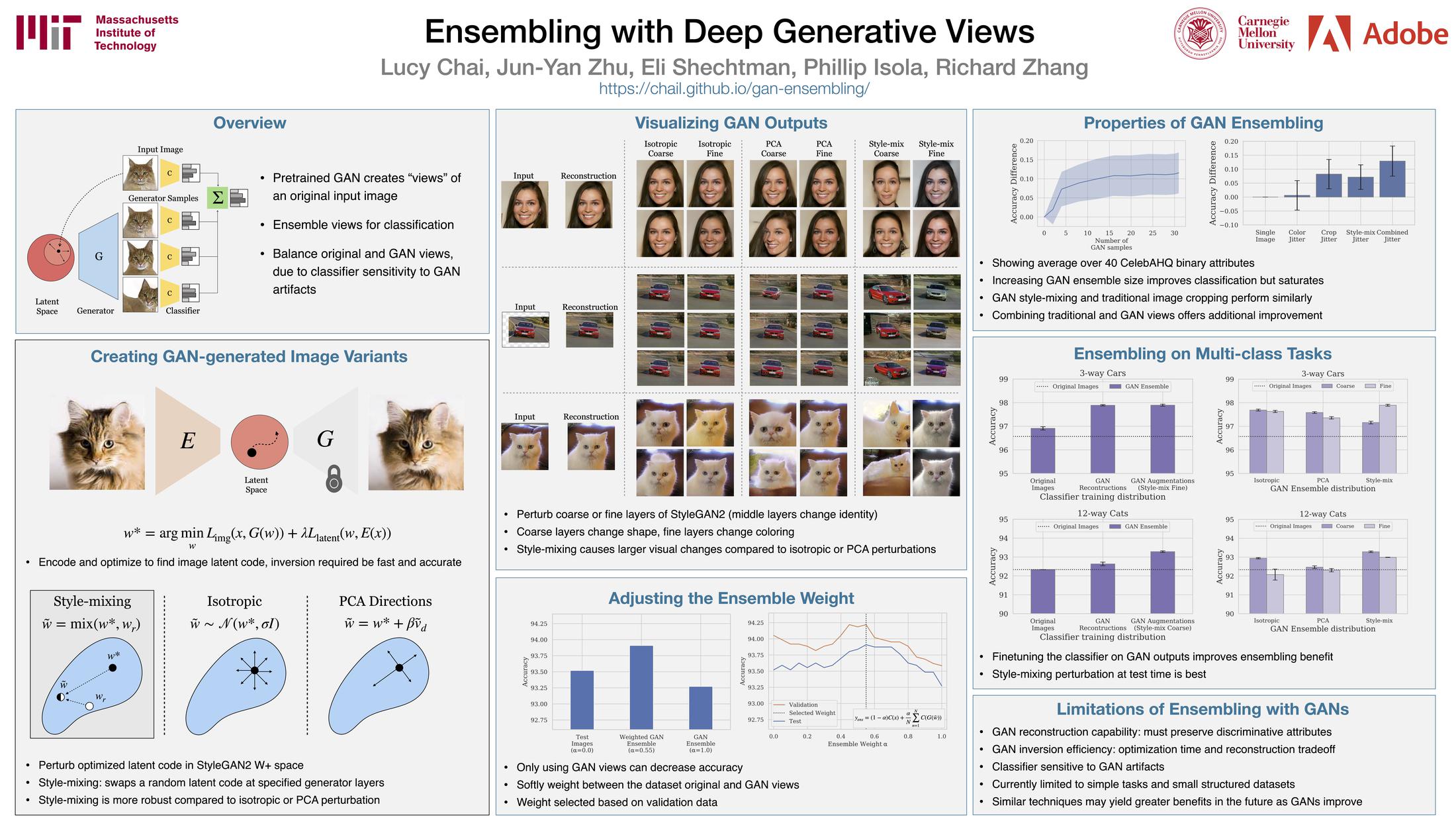
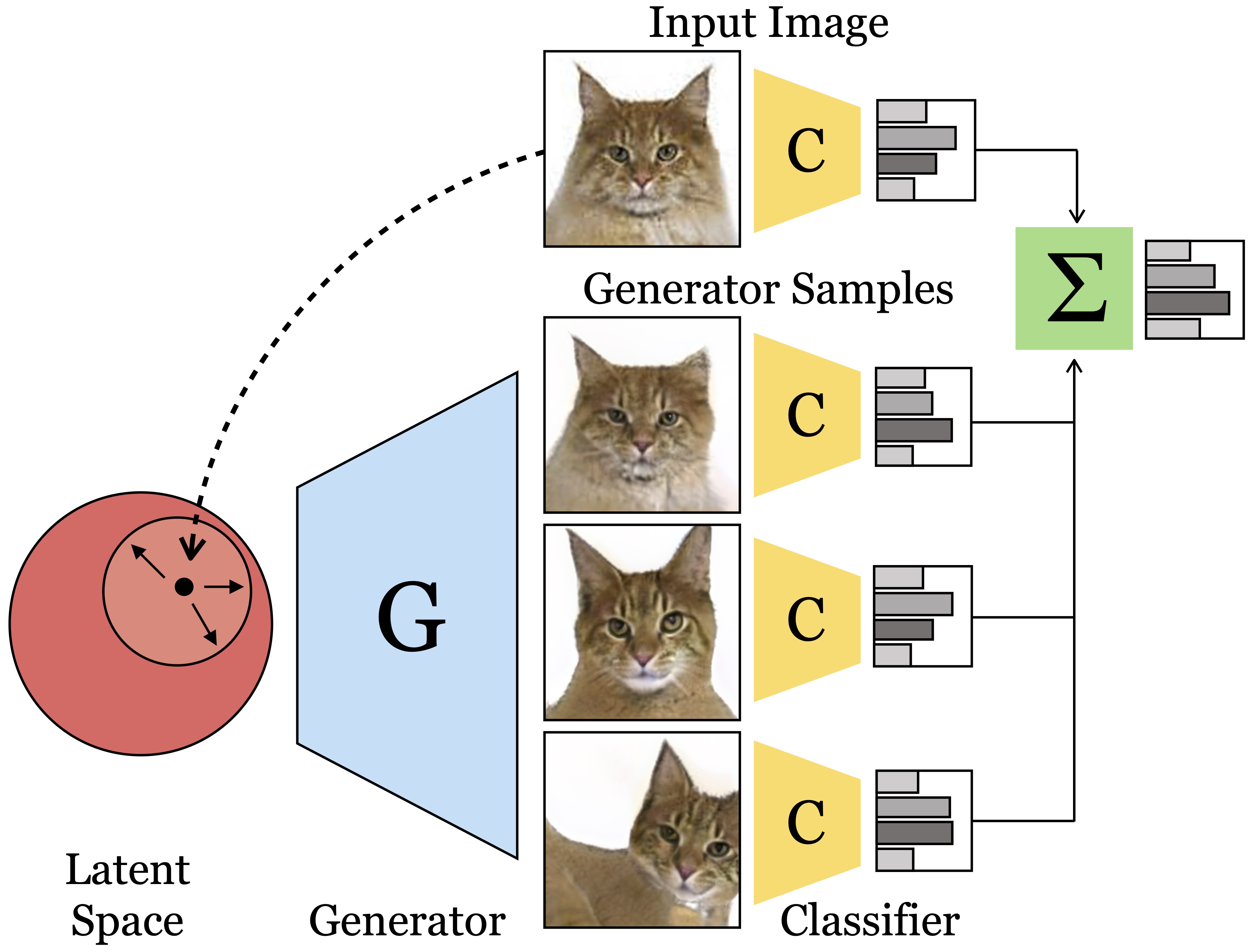
Recent generative models can synthesize ''views'' of artificial images that mimic real-world variations, such as changes in color or pose, simply by learning from unlabeled image collections. Here, we investigate whether such views can be applied to real images to benefit downstream analysis tasks, such as image classification. Using a pretrained generator, we first find the latent code corresponding to a given real input image. Applying perturbations to the code creates natural variations of the image, which can then be ensembled together at test-time. We use StyleGAN2 as the source of generative augmentations and investigate this setup on classification tasks on facial attributes, cat faces, and cars. Critically, we find that several design decisions are required towards making this process work; the perturbation procedure, weighting between the augmentations and original image, and training the classifier on synthesized images can all impact the result. Currently, we find that while test-time ensembling with GAN-based augmentations can offer some small improvements, the remaining bottlenecks are the efficiency and accuracy of the GAN reconstructions, coupled with classifier sensitivities to artifacts in GAN-generated images.
Summary
We investigate different methods of perturbing the optimized latent code of a given image, using isotropic Gaussian noise, unsupervised PCA axes in the latent space, and a "style-mixing" operation at both coarse and fine layers. On the CelebA-HQ domain, we find that style-mixing on fine layers generalizes best to the test partition. Below, we show qualitative examples of the style-mixing operation on coarse and fine layers on several domains.

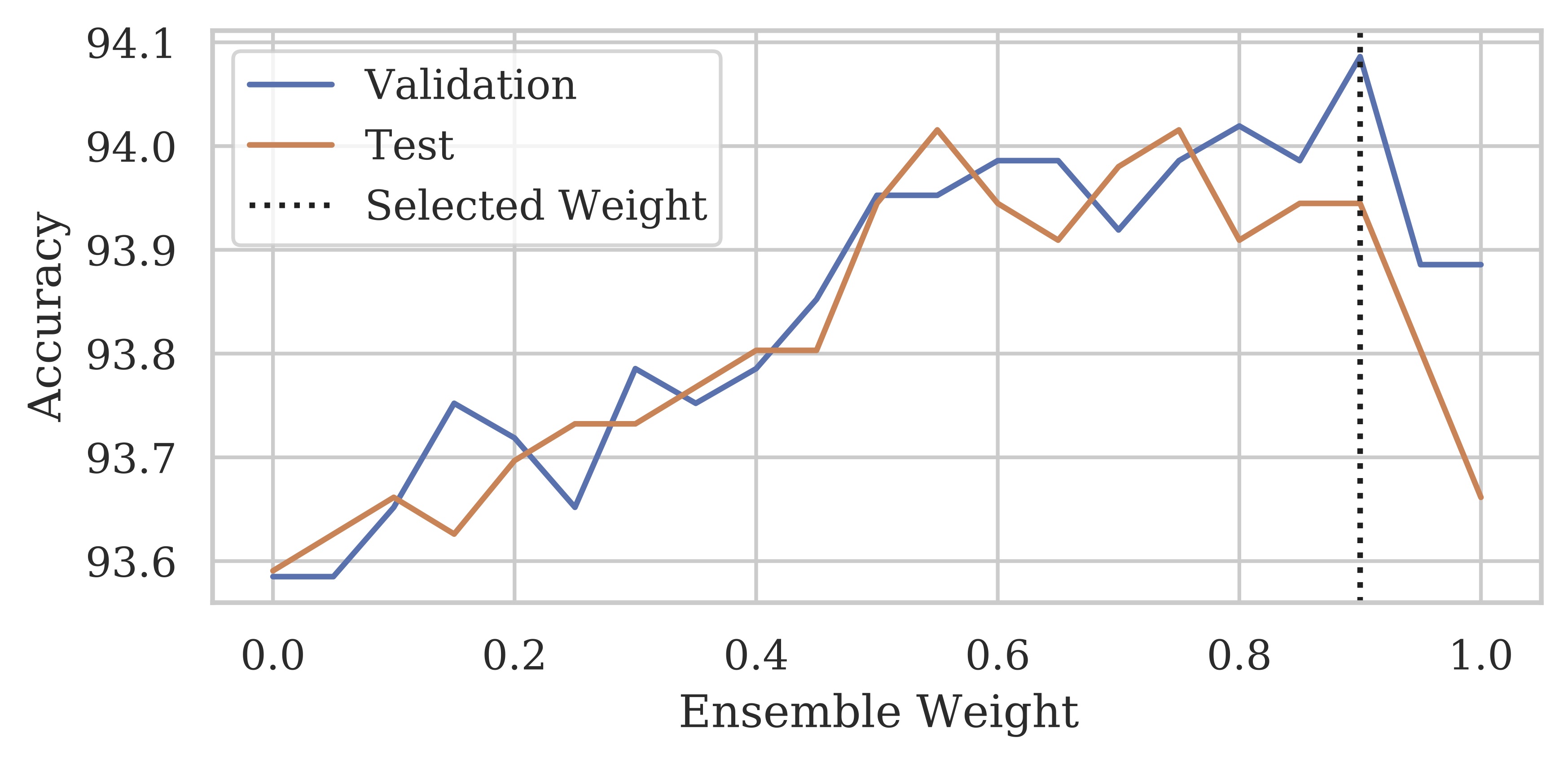
We find that an intermediate weighting between the original image and the GAN-generated variations improves results, using an ensemble weight parameter α. Here, we show this effect on the CelebA-HQ smiling attribute. We select this parameter using the validation split, and apply it to the test split.
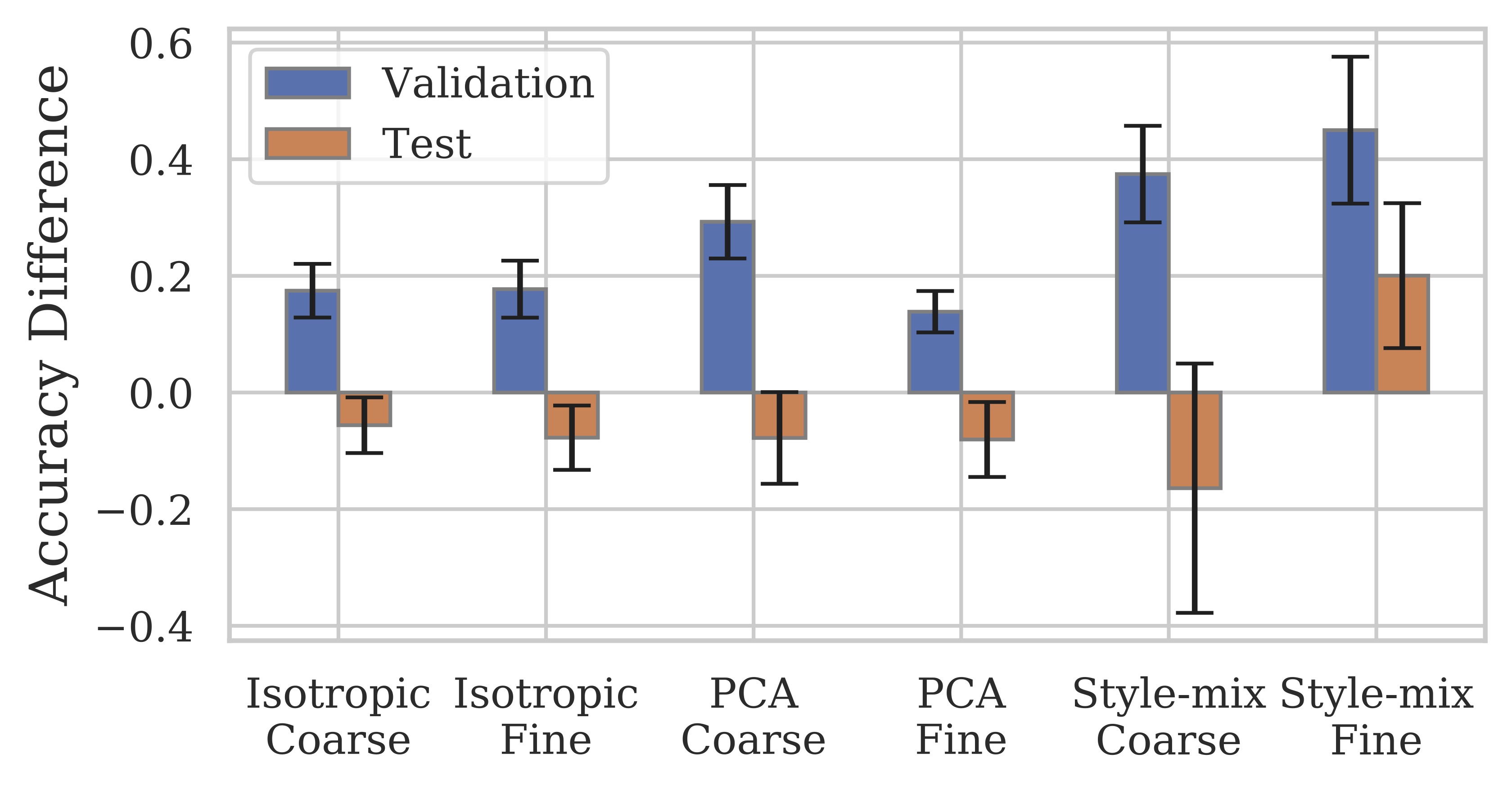
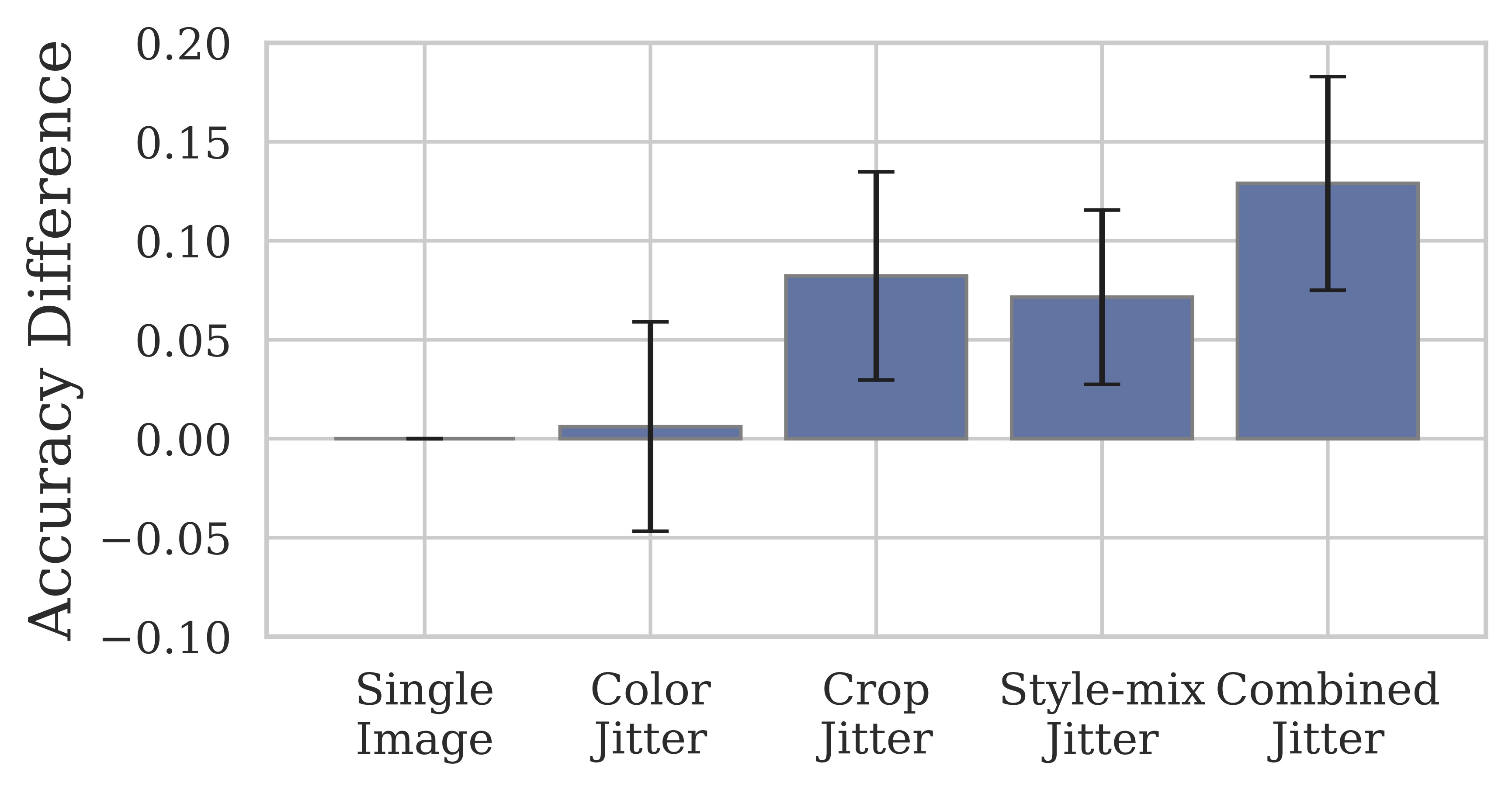
Averaged over 40 CelebA-HQ binary attributes, ensembling the GAN-generated images as test-time augmentation performs similarly to ensembling with small spatial jitter. However, the benefits are greater when both methods are combined. We plot the different between the test-time ensemble accuracy and standard single-image test accuracy.
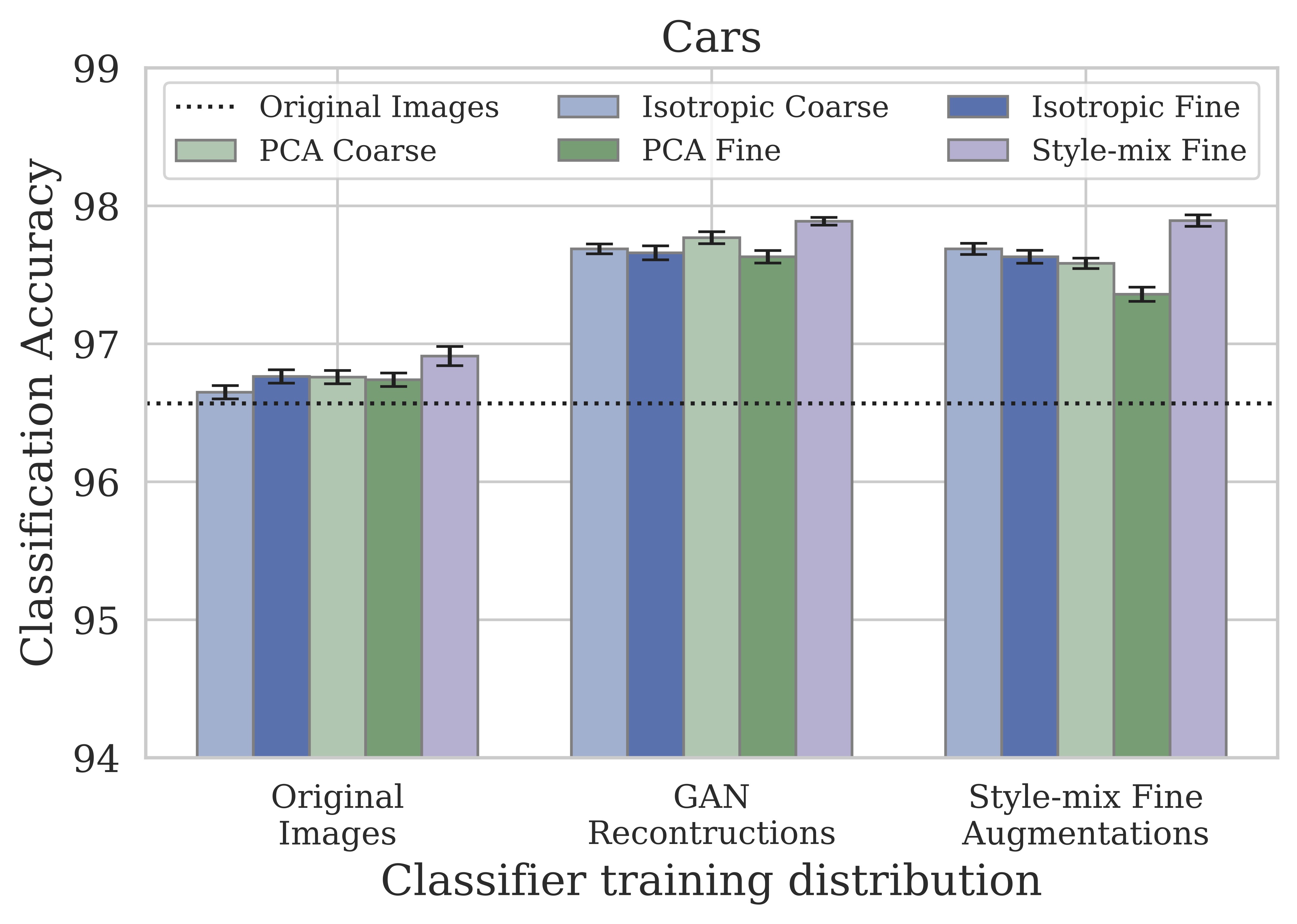
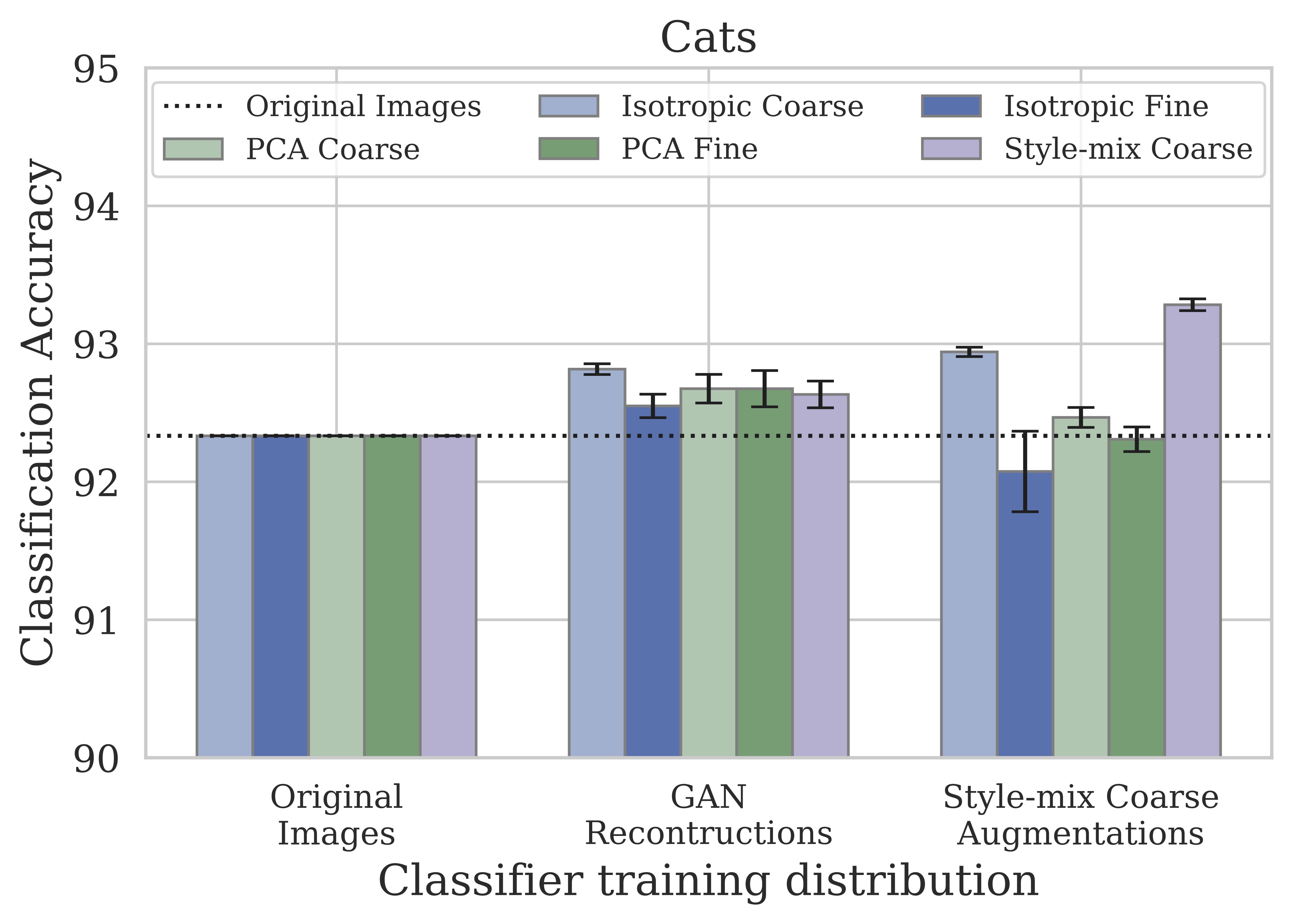
We also experiment on a three-way classification task on cars, and a 12-way classification task on cat faces. In these domains, the style-mixing operation is also the most beneficial, which corresponds to greater visual changes compared to isotropic and PCA perturbations.
There are some important limitations and challenges of the current approach.
(1) Inverting images into GANs: the inversion must be accurate enough such that classification on the GAN-generated reconstruction is similar to that of the original image. Getting a good reconstruction can be computationally expensive, and some dataset images are harder to reconstruct, which limits us to relatively simple domains.
(2) Classifier sensitivities: the classifier can be sensitive to imperfect GAN reconstructions, so classification accuracy tends to drop on the GAN reconstructions alone. We find that it helps to upweight the predictions on the original image relative to the GAN-generated variants in the ensemble, but ideally, the classifier should behave similarly on real images and GAN-generated reconstructions.
Reference
L Chai, JY Zhu, E Shechtman, P Isola, R Zhang. Ensembling with Deep Generative Views.
CVPR, 2021.
@inproceedings{chai2021ensembling,
title={Ensembling with Deep Generative Views.},
author={Chai, Lucy and Zhu, Jun-Yan and Shechtman, Eli and Isola, Phillip and Zhang, Richard},
booktitle={CVPR},
year={2021}
}
Acknowledgements:
We would like to thank Jonas Wulff, David Bau, Minyoung Huh, Matt Fisher, Aaron Hertzmann, Connelly Barnes, and Evan Shelhamer for helpful discussions. LC is supported by the National Science Foundation Graduate Research Fellowship under Grant No. 1745302. This work was started while LC was an intern at Adobe Research. Recycling a familiar template.